Training the LLM model
Now that you have installed the notebook, configured the AWS CLI, and created an Amazon S3 bucket, let's run your model on the notebook.
In this resource, we will use the Hugging Face Transformers library to fine-tune a pre-trained model, i.e. prajjwal1/bert-tiny, on a small subset of the AG News dataset for text classification.
Note: Hugging Face is an open-source library providing a wide range of pre-trained models and tools for natural language processing tasks. AG News is a dataset consisting of news articles from various sources and it is commonly used for text classification tasks. prajwall1/bert-tiny is a very small version of the BERT model, which is a transformer-based model pre-trained on a large corpus of text data.
What will you learn?
- How to train your LLM model using the Hugging Face Transformers library
What do you need before starting?
- Met all prerequisites
- Completed previous steps
How to train the LLM model
Now, we’ll cover the code you’ll need for the notebook. NOTE: remember to change the bucket name to your own bucket’s name. Instructions and descriptions are included in-line and denoted by the “#” character, so that you may copy the entire code block:
# install the necessary libraries
!pip install transformers datasets torch evaluate accelerate boto3
# import the necessary functions and APIs
import numpy as np
import evaluate
import boto3
import os
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
# disable tokenizers parallelism warning
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# load a portion of the AG News dataset (500 examples)
dataset = load_dataset("ag_news")
small_dataset = dataset["train"].shuffle(seed=42).select(range(500))
# load the model (prajjwal1/bert-tiny), tokenizer, and pre-trained model
model_name = "prajjwal1/bert-tiny"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=4)
# define the function to tokenize text examples using the loaded tokenizer
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# apply the tokenize_function to the small_dataset using map function
tokenized_datasets = small_dataset.map(tokenize_function, batched=True)
# specify the training arguments, i.e. output directory, evaluation strategy, learning rate, batch size, number of epochs, weight decay, and load the best model at the end
training_args = TrainingArguments(
output_dir="./results",
eval_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
load_best_model_at_end=True,
)
# load the accuracy metric from the evaluate library
metric = evaluate.load("accuracy")
# compute evaluate metrics by taking the eval predictions (logits and labels) and calculate the accuracy using the loaded metric
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# set up the training process by taking the model, training arguments, train and eval datasets, tokenizer and the compute_metrics function
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets,
eval_dataset=tokenized_datasets,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
# start the training process using the configured trainer
trainer.train()
# save the model and tokenizer into model folder
model_save_dir = "./model"
tokenizer.save_pretrained(model_save_dir)
model.save_pretrained(model_save_dir)
# upload the saved model to s3 bucket
s3_client = boto3.client('s3')
bucket_name = 'llm-bucket-dsari' # please change this with your own bucket name
model_save_path = 'model/'
for file_name in os.listdir(model_save_dir):
s3_client.upload_file(
os.path.join(model_save_dir, file_name),
bucket_name,
model_save_path + file_name
)In summary, the code loads the dataset, tokenizes the text examples, sets up the training arguments, defines the evaluation metrics, and trains the model using the Trainer class. Finally, it saves the trained model and tokenizer locally and then uploads and saves them to the S3 bucket.
After you run it, you should see an output similar to the following (note that this may vary):
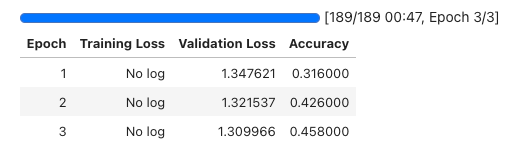
Here, the results suggest that the model is learning and improving over the epochs based on the increasing accuracy and decreasing losses. However, the final accuracy of only 45.8% is low, indicating that the model's performance is suboptimal.
This is understandable, because the model is trained on a very small subset of the dataset, i.e. 500 examples, and we're also using a very small version of the BERT model, (prajjwal1/bert-tiny). With this in mind, you might want to try a larger dataset and larger model in your experiment. In addition, you could also fine-tune the hyperparameters to make it more optimal for the training process. We will cover this optional step in the next resource.
Possible error notes
You may see the following errors during the above steps. Many of them are expected in the scenario we’re using for this learning path, and are not cause for concern:
- Unable to register cuDNN/cuFFT/cuBLAS factory...: These errors are informational and generally harmless. They indicate that multiple components are trying to initialize the same CUDA libraries, but it shouldn't affect the training process.
- This TensorFlow binary is optimized to use available CPU instructions...: This is a warning from TensorFlow indicating that your CPU may not support certain instructions (AVX2, AVX512F, FMA), and since we're not using a GPU, this warning is expected.
- TF-TRT Warning: Could not find TensorRT: TensorRT is NVIDIA's library for optimizing deep learning models. This warning just means that it's not available, which is fine since we're not using it.
- Some weights of BertForSequenceClassification were not initialized...: This is a standard message when you're fine-tuning a model. It indicates that some parts of the model will be trained from scratch to adapt to your specific task, i.e. text classification on AG News.
Remember to save the notebook
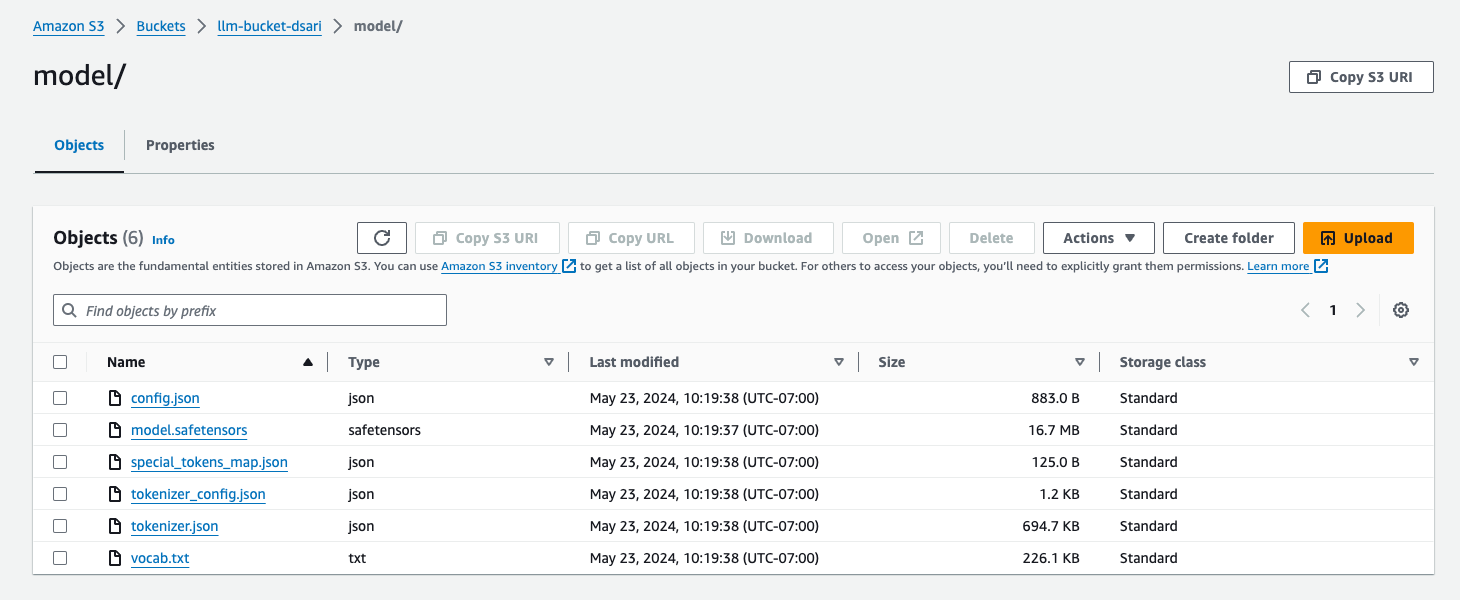
Last but not least, do not forget to save your notebook. On your left tab, you will see the model folder where the results, i.e. the model and tokenizer, were saved. You can also see the results folder and, within it, the runs folder for every run you make. In addition, if you go to the S3 bucket in the console, you will see the output stored in the model folder:
With that, you’re ready to move on to the next resource.
