Performing hyperparameter tuning
This learning path has been a very simple guide aimed to get you started with Red Hat® OpenShift® AI (RHOAI) and Red Hat OpenShift Service on AWS (ROSA). As mentioned previously, you could improve the accuracy in your training by increasing the dataset size and running a more robust model. We can leverage GPU to support that. Another idea is to extend the workload to AWS SageMaker and/or to AWS Lambda. In addition, RHOAI itself has a section where you can run the code as a pipeline.
What will you learn?
- How to conduct hyperparameter tuning to increase accuracy
What do you need before starting?
- Met all prerequisites
- Completed previous steps
Steps to perform hyperparameter tuning
There are many ways to go about performing hyperparameter tuning for your model to improve the model accuracy. Here we’ll be using optuna, which is a popular library to optimize hyperparameters. It essentially allows you to define the search space for each hyperparameter and automatically finds the best combination based on the specified objective.
This is the code example that you can run on the notebook. Once again, instructions and descriptions are included in-line and denoted by the “#” character, so that you may copy the entire code block:
!pip install transformers datasets torch evaluate accelerate boto3 optuna
import numpy as np
import evaluate
import optuna
import boto3
import os
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
os.environ["TOKENIZERS_PARALLELISM"] = "false"
dataset = load_dataset("ag_news")
small_dataset = dataset["train"].shuffle(seed=42).select(range(500))
model_name = "prajjwal1/bert-tiny"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=4)
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = small_dataset.map(tokenize_function, batched=True)
def compute_metrics(eval_pred):
metric = evaluate.load("accuracy")
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# define the objectives, i.e. the hyperparameters to tune, the training arguments, train the model, and evaluate them
def objective(trial):
learning_rate = trial.suggest_loguniform("learning_rate", 1e-5, 5e-5)
per_device_train_batch_size = trial.suggest_categorical("per_device_train_batch_size", [4, 8, 16])
num_train_epochs = trial.suggest_int("num_train_epochs", 2, 4)
training_args = TrainingArguments(
output_dir="./results",
eval_strategy="epoch",
save_strategy="epoch",
learning_rate=learning_rate,
per_device_train_batch_size=per_device_train_batch_size,
num_train_epochs=num_train_epochs,
weight_decay=0.01,
load_best_model_at_end=True,
)
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets,
eval_dataset=tokenized_datasets,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()
eval_metrics = trainer.evaluate()
return eval_metrics["eval_accuracy"]
# run hyperparameter search
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=9)
# find the best parameter and accuracy
best_params = study.best_params
best_accuracy = study.best_value
print("Best hyperparameters:", best_params)
print("Best accuracy:", best_accuracy)
# train the model with the best hyperparameters
best_model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=4)
trainer = Trainer(
model=best_model,
args=TrainingArguments(
output_dir="./results",
eval_strategy="epoch",
save_strategy="epoch",
learning_rate=best_params["learning_rate"],
per_device_train_batch_size=best_params["per_device_train_batch_size"],
num_train_epochs=best_params["num_train_epochs"],
weight_decay=0.01,
load_best_model_at_end=True,
),
train_dataset=tokenized_datasets,
eval_dataset=tokenized_datasets,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()
model_save_dir = "./model"
tokenizer.save_pretrained(model_save_dir)
best_model.save_pretrained(model_save_dir)
s3_client = boto3.client('s3')
bucket_name = 'llm-bucket-dsari' # please change this to your bucket name
model_save_path = 'model/'
for file_name in os.listdir(model_save_dir):
s3_client.upload_file(
os.path.join(model_save_dir, file_name),
bucket_name,
model_save_path + file_name
)Here we are using the same dataset and the same model. However, the main difference between this code and the one before is that here we define an objective function that takes an optuna trial as input, and we create a Trainer instance with the tuned hyperparameters and train the model.
Then, we create an optuna study and optimize the objective function. Finally, we retrieve the best hyperparameter and its accuracy. Note that the code could run for a bit longer than before, as it keeps running trials and the final results may vary. In this case, the final epoch reaches 94.6% accuracy.
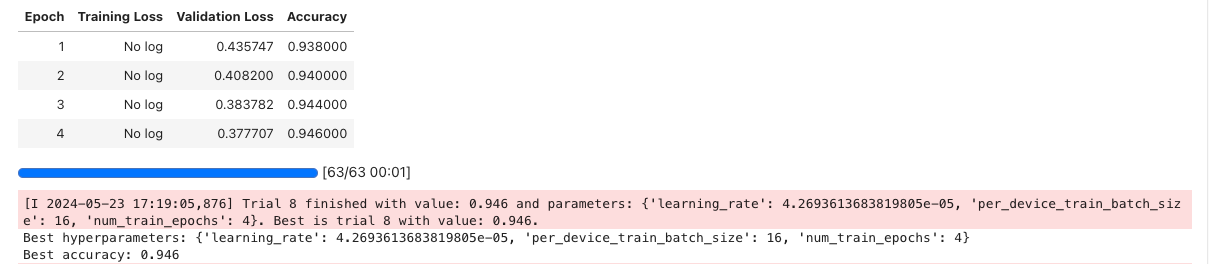
Note that this is just an example of hyperparameter tuning and that there are many other methods that you can try, such as grid and random search or Bayesian optimization. Many machine learning frameworks and libraries already have built-in utilities for hyperparameter tuning, which makes it easier to apply in practice.
