One of the key features OpenShift offers is the ability to go beyond just running containers in a cluster by also enabling developers to build their applications directly on the platform. For OpenShift 3.3, we’ve added a number of features to improve the developer workflow when developing and testing applications on OpenShift.
Pipelines
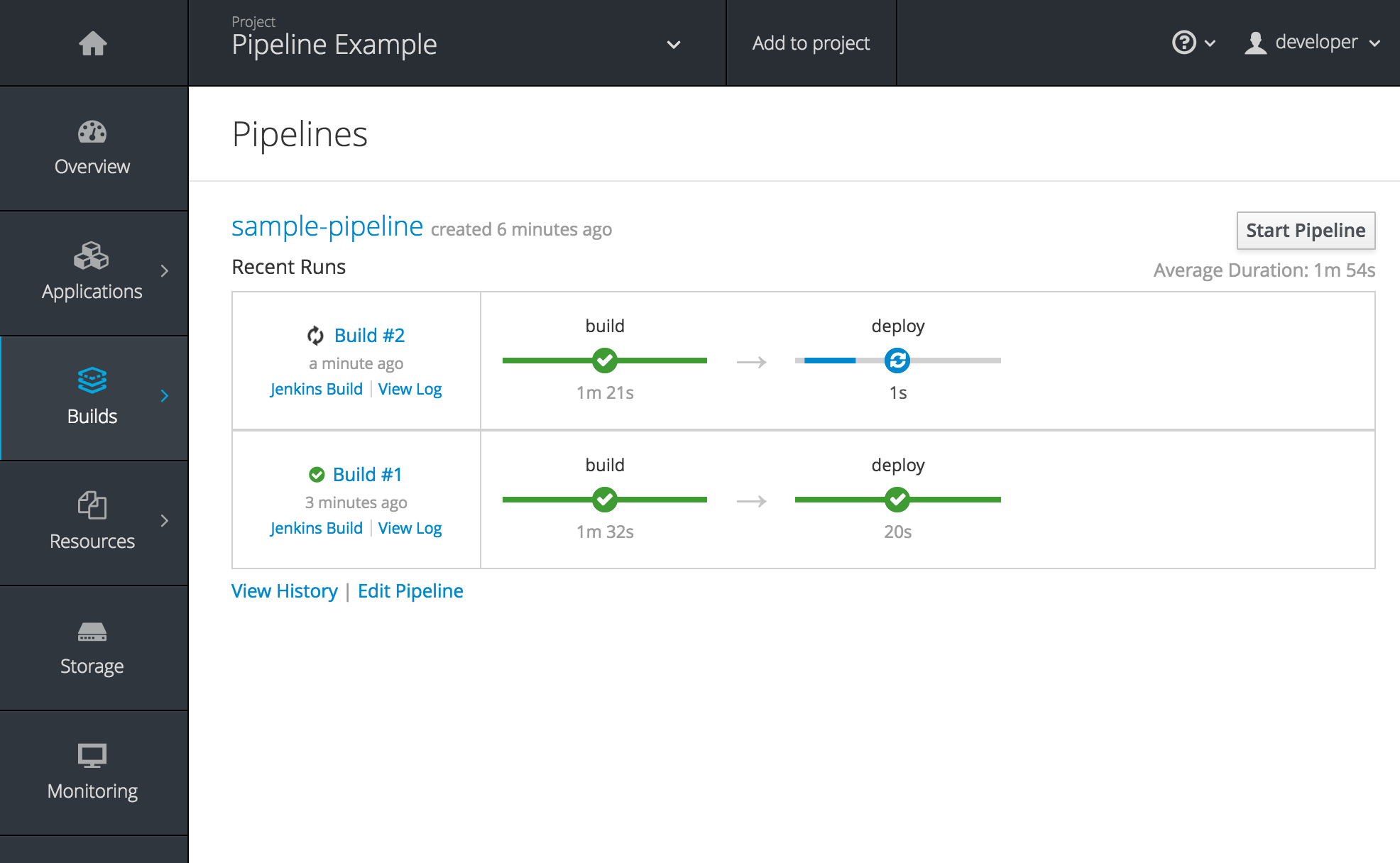
With OpenShift 3.3, OpenShift’s CI/CD story continues to evolve. While previously it was possible to define small pipeline-like workflows such as triggering deployments after a new image was built, or building an image when upstream source code changed, OpenShift Pipelines (tech preview) expose a true first class pipeline execution capability. OpenShift Pipelines are based on the Jenkins Pipeline plugin. By integrating Jenkins Pipelines into OpenShift, you can now leverage the full power and flexibility of the Jenkins ecosystem while managing your workflow from within OpenShift.

Pipelines are defined as a new build strategy within OpenShift, meaning you can start, cancel, and view your pipelines in the same way as any other build. Because your pipeline is executed by Jenkins, you can also use the Jenkins console to view and manage your pipeline. Finally, your pipelines can utilize the OpenShift Pipeline plugin to easily perform first class actions in your OpenShift cluster, such as triggering builds and deployments, tagging images, or verifying application status.
To keep the system fully integrated, the Jenkins server executing your pipeline can run within your cluster, launch Jenkins slaves on that same cluster, and OpenShift can even automatically deploy a Jenkins server if one does not already exist when you first declare a new pipeline build configuration.
We’ll have an in depth blog fully covering this new feature up shortly, in the meantime you can read the pipeline documentation:
For additional details of changes made to the OpenShift web console, check out What's New in OpenShift 3.3 - Web Console.
Jenkins Plugin Enhancements
The plugin now provides full integration with the Jenkins Pipeline, exposing the same OpenShift build steps available in the classic, “freestyle” jobs as Jenkins Pipeline DSL methods (replacing the Java language invocations previously available from the Jenkins Pipeline Groovy scripts).
Several user requested features have also been introduced, including:
- Exposing “Scale OpenShift Deployments” as a post-build action
- Additional configuration available at the specific step level for triggering builds and deployments
- Embeddable use of job parameters for configuration of specific step fields
Check out the documentation on the OpenShift Jenkins plugin for more details.
Easy and Quick Development Cluster Setup
Often times a developer will want to have a standalone OpenShift instance running on their desktop to enable evaluation of various features or developer and testing locally of their containerized applications containers. Launching a local instance of OpenShift for application development is now as easy as downloading the latest OpenShift client tools and running:
<span>$ oc cluster up</span>
This will give you a running cluster using your local docker daemon or Docker Machine. All the basic infrastructure of the cluster is auto-configured for you: a registry, router, imagestreams for standard images, and sample templates.
It also creates a normal user and system administrator accounts for managing the cluster. Watch this space for a follow up blog detailing everything oc cluster up is doing under the covers to make your environment ready to use.
Serialized Build Execution
Prior to OpenShift 3.3, if multiple builds were created for a given build configuration, they all ran in parallel. This resulted in a race to the finish, with the last build to push an application image to the registry winning. This also lead to higher resource utilization peaks when multiple builds ran at the same time. Now with OpenShift 3.3, builds run serially by default. It is still possible to revert to the parallel build policy if desired. In addition, we have introduced a SerialLatestOnly policy which will run builds in serial, but skip intermediary builds. In other words, if build 1 is running and builds 2, 3, 4, and 5 are in the queue, when build 1 completes the system will cancel builds 2-4 and immediately run build 5. This allows you to optimize your build system around building the latest code and not waste time building intermediate commits.
For more information, see OpenShift documentation topic on build run policy.
Enhanced Source Code Synchronization
OpenShift previously offered an “oc rsync” command for synchronizing a local filesystem to a running container. This is a very useful tool for copying files into a container in general, but in particular it can be used to synchronize local source code into a running application framework. For frameworks that support hot deployment when files change, this enables an extremely responsive code/save/debug workflow with source on the developer’s machine using the their IDE of choice, while the application runs in the cloud with access to any service it depends on such as databases.
We’ve made this sync flow even easier by coupling it with a filesystem watch. Instead of manually syncing changes, developers can now run “oc rsync --watch” which launches a long running process that will monitor the local filesystem for changes and continuously sync them to the target container. Assuming the target container is running a framework that supports hot reload of source code, the development workflow is now “save file in IDE, reload application page in browser, see changes.”
For more information, see OpenShift documentation topic on syncing file changes.
Build Trigger Cause Tracking
While OpenShift has always automatically run a build of your application when source changes or an upstream image that your application is built on top of has been updated, prior to OpenShift 3.3 it wasn’t easy to know why your application had been rebuilt. With OpenShift 3.3, builds now include information explaining what triggered the build (manual, image change, webhook, etc) as well as details about the change such as the image or commit id associated with the change.
A build triggered by a image change
Output provided by CLI command "oc describe build":
$ oc describe build ruby-sample-build-2
Name: ruby-sample-build-2
…………….
Status: Running
Started: Fri, 09 Sep 2016 16:39:46 EDT
Duration: running for 10s
Build Config: ruby-sample-build
Build Pod: ruby-sample-build-2-buildStrategy: Source
URL: https://github.com/openshift/ruby-hello-world.git
From Image: DockerImage centos/ruby-23-centos7@sha256:940584acbbfb0347272112d2eb95574625c0c60b4e2fdadb139de5859cf754bf
Output to: ImageStreamTag origin-ruby-sample:latest
Post Commit Hook: ["", "bundle", "exec", "rake", "test"]
Push Secret: builder-dockercfg-awr0vBuild trigger cause:Image change
Image ID:centos/ruby-23-centos7@sha256:940584acbbfb0347272112d2eb95574625c0c60b4e2fdadb139de5859cf754bf
Image Name/Kind: ruby:latest / ImageStreamTag
Then within the web console:

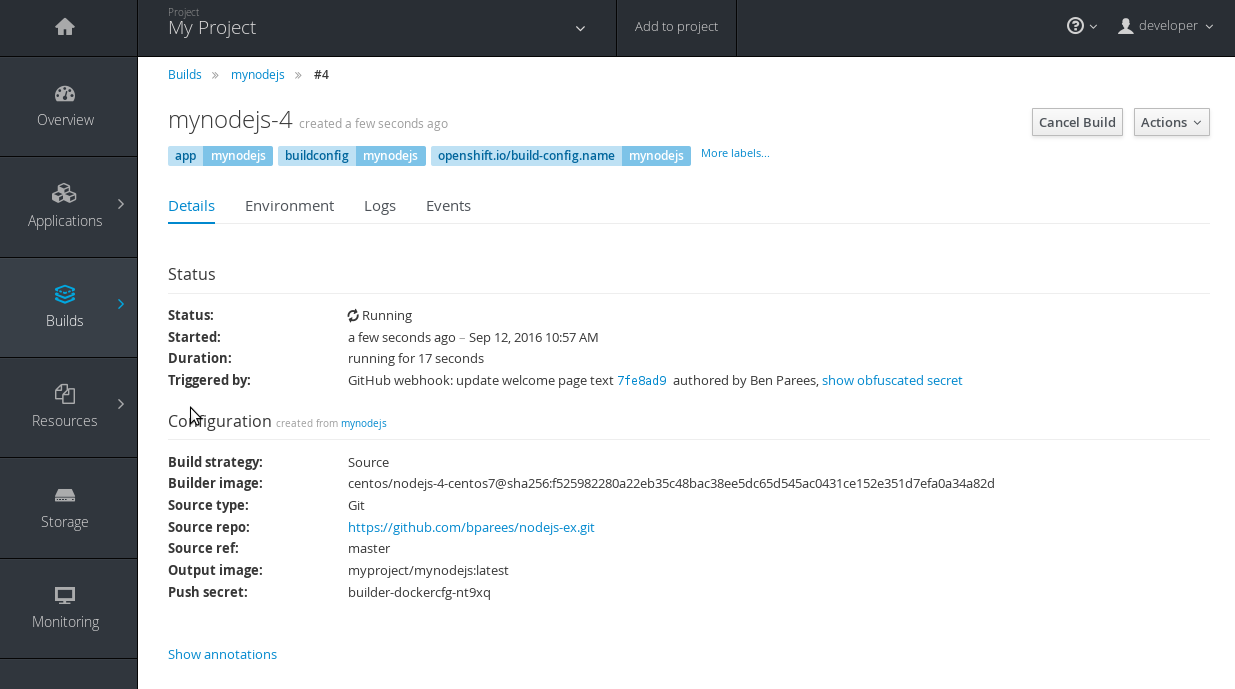
A build triggered by a webhook
Output provided by CLI command "oc describe build":
$ oc describe build mynodejs-4
Name: mynodejs-4
…………...
Status: Complete
Started: Mon, 12 Sep 2016 04:57:44 EDT
Duration: 20s
Build Config: mynodejs
Build Pod: mynodejs-4-buildStrategy: Source
URL: https://github.com/bparees/nodejs-ex.git
Ref: master
Commit: 7fe8ad9 (update welcome page text)
Author/Committer: Ben Parees
From Image: DockerImage centos/nodejs-4-centos7@sha256:f525982280a22eb35c48bac38ee5dc65d545ac0431ce152e351d7efa0a34a82d
Output to: ImageStreamTag mynodejs:latest
Push Secret: builder-dockercfg-nt9xqBuild trigger cause:GitHub WebHook
Commit:7fe8ad9 (update welcome page text)
Author/Committer:Ben Parees
Secret: 34c64fd2***
Then within the web console:
Webhook Improvements
It’s now possible to provide additional inputs to webhook triggered builds. Previously the generic webhook simply started a new build with all the default values inherited from the build configuration. It’s now possible to provide a payload to the webhook API. The payload can provide git information so that a specific commit or branch can be built. Environment variables can also be provided in the payload. Those environment variables are made available to the build in the same way as environment variables defined in the build configuration.
For examples of how to define a payload and invoke the webhook, check out the documentation on generic webhooks.
Self Tuning Images
OpenShift provides a number of framework images for working with Java, Ruby, PHP, Python, NodeJS, and Perl code. It also provides a few database images (MySQL, MongoDB, PostgreSQL) out of the box. For OpenShift 3.3 we’ve made these images even better by making them self-tuning. Based on the container memory limits specified when the images are deployed, these images will auto-configure things like heap sizes, cache sizes, number of worker threads, etc. Of course all these auto-tuned values can easily be overridden by environment variables as well.
Summary
You can get your hands on the developer experience in all the various offerings for OpenShift 3.3. We look forward to getting your feedback on what you like, what you don't and scenarios that you'd like to have supported. Be on the look out for experience surveys and other mechanisms to help us drive the improvements.
Related Posts
If you want to learn more about the new features of OpenShift 3.3 Don't miss the following blog posts from our engineering team:
What’s New in OpenShift 3.3 – Cluster Management
About the author

{kind=link}
{kind=link}
More like this
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech