
This post was originally written by Markus Eisele in his blog: http://blog.eisele.net/2015/07/scaling-and-load-balancing-wildfly-with-fabric8-openshift.html
The first two parts of this little series introduced you build a tiny JAX-RS service with WildFly Swarm and package it into a Docker image. You learned how to deploy this example to OpenShift and now it is time to scale it up a bit.
Why Scaling Is Important
One of the key aspects of microservices based architectures is decomposition into highly performant individual services which scale on demand and technically easy. Applications are now being built to scale and infrastructure is transparently assisting where necessary.
Java EE developers have done this a lot in the past with the standard horizontal scaling by putting more physical boxes next to each other, or limit vertical scaling by spinning up more instances on the same host.
Microservices allow for different scaling approaches. A much more complete definition of the different variations for scaling can be found in the book The Art Of Scalability.
I'm going to dig into different approaches with future blog-posts. To make this intro into scaling a little bit easier, today we're going to scale our tiny little app vertically by spinning up more pods for it.
What Is A Pod
A pod (as in a pod of whales or pea pod) is a Kubernetes object which corresponds to a colocated group of applications running with a shared context.
In terms of Docker constructs, a pod consists of a colocated group of Docker containers with shared volumes. In a pre-container world, they would have executed on the same physical or virtual host. So, that's what we want to scale in this example. The pod, that is already running.
What Did We Do So Far?
When you first deployed the JAX-RS example, OpenShift created a bunch of resources. Namely:
- Imagestream
An image stream is similar to a Docker image repository in that it contains one or more Docker images identified by tags. OpenShift stores complete metadata about each image (e.g., command, entrypoint, environment variables, etc.). Images in OpenShift are immutable. OpenShift components such as builds and deployments can watch an image stream and receive notifications when new images are added, reacting by performing a build or a deployment, for example. - Service
A Kubernetes service serves as an internal load balancer. It identifies a set of replicated pods in order to proxy the connections it receives to them. - DeploymentConfig
Building on replication controllers, OpenShift adds expanded support for the software development and deployment lifecycle with the concept of deployments. OpenShift deployments also provide the ability to transition from an existing deployment of an image to a new one and also define hooks to be run before or after creating the replication controller.
So, a service proxies our request to the pods, and a deploymentconfig is build on top of the Kubernetes replication controller, which controls the number of pods. We're getting closer!
Scale My Microservice now, please!
Just wait a second. While services provide routing and load balancing for pods which may blink in and out of existence, ReplicationControllers (RC) are used to specify and enforce the number of pods (replicas) that should be in existence.
RCs can be thought of to live at the same level as Services but they provide different functionality above pods. RCs are a Kubernetes object. OpenShift provides a “wrapper” object on top of the RC called a Deployment Configuration (DC). DCs not only include the RC but they also allow you to define how transitions between images occur as well as postdeploy hooks and other deployment actions.
We finally know where to look at. Let's seem what the DeploymentConfig looks like, that we created when we started our swarm-sample image.
<code>oc get dc swarm-sample</code>
NAME TRIGGERS LATEST VERSION
swarm-sample ConfigChange, ImageChange 1
Even though RCs control the scaling of the pods, they are wrapped in a higher construct, DeploymentConfig, which also manages when, where, and how these Pods/RCs will be deployed. We can still see the underlying RC: (note: output truncated)
<code>oc get rc swarm-sample-1</code>
CONTROLLER CONTAINER(S) IMAGE(S) REPLICAS
swarm-sample-1 swarm-sample 172.30.101.151:5000/myfear/swarm-sample@sha256:[...] 1
And now we need to know if whatever scaling we're going to do is actually working. I did push a little curl script, which outputs the result from the JAX-RS endpoint and sleeps for 2 seconds before it is requesting the output again.
Start it up and watch the result returning the same hostname environment variable all over until you execute the following command:
<code>oc scale dc swarm-sample --replicas=3</code>
Now everything changes and after a while you see three different hostnames being returned. It might take a while (depending on your machine and how quickly OpenShift can spin up the new pods.You can also see the change in the admin console, where three pods are now displayed.

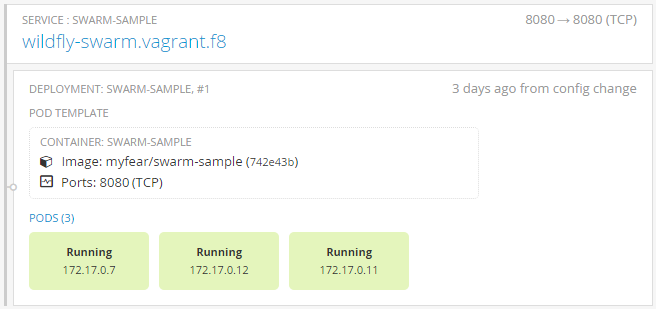{kind=link}
We can revert the behavior by setting the replicas count back to 1.
<code>oc scale dc swarm-sample --replicas=1</code>
That was easy. And not exactly considered best-practice. Because all of the pods share the same context, they should never run on the same physical machine. Instead, it would be better to run a complete microservice (frontend, backend, database) on three pods within the same RC.
But this is a topic for more blog-posts to come. Now you learned how to scale pods on OpenShift and we can continue to evolve our example application further and do more scaling examples later.
Author
Markus Eisele
Developer Advocate
JBoss Middleware at Red Hat
@myfear
http://blog.eisele.net/
About the author

Markus Eisele is a Red Hat Developer Tools Marketing Lead at Red Hat. He is also a JavaTM Champion, former Java EE Expert Group member, founder of German JavaLand and a speaker at Java conferences around the world.
Browse by channel

Automation
The latest on IT automation that spans tech, teams, and environments

Artificial intelligence
Explore the platforms and partners building a faster path for AI

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
Explore how we reduce risks across environments and technologies

Edge computing
Updates on the solutions that simplify infrastructure at the edge

Infrastructure
Stay up to date on the world’s leading enterprise Linux platform

Applications
The latest on our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech
Products
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud services
- See all products
Tools
- Training and certification
- My account
- Developer resources
- Customer support
- Red Hat value calculator
- Red Hat Ecosystem Catalog
- Find a partner
Try, buy, & sell
Communicate
About Red Hat
We’re the world’s leading provider of enterprise open source solutions—including Linux, cloud, container, and Kubernetes. We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
Select a language
Red Hat legal and privacy links
- About Red Hat
- Jobs
- Events
- Locations
- Contact Red Hat
- Red Hat Blog
- Diversity, equity, and inclusion
- Cool Stuff Store
- Red Hat Summit