Jupyter Notebooks
You will need the following prerequistes in order to run a basic Jupyter notebook with GPU on OpenShift
1. A OpenShift Cluster
This will assume you have already provisioned a OpenShift cluster succesfully and are able to use it.
You will need to log in as cluster admin to deploy GPU Operator .
2. OpenShift Command Line Interface
Please see the OpenShift Command Line section for more information on installing.
The following guides through a step by step procedure in deploying Jupyter Notebook in OpenShift.
3. Reference images
You’ll be doing the majority of the labs using the OpenShift CLI, but you can also accomplish them using the OpenShift web console. You can create a minimal Jupyter notebook image using the Source-to-Image (S2I) build process. The image can be built in OpenShift, separately using the s2i tool, or using a docker build. One can deploy a custom notebook image. The Jupyter Project provides a number of images for notebooks on Docker Hub. These are:
- base-notebook
- r-notebook
- minimal-notebook
- scipy-notebook
- tensorflow-notebook
- datascience-notebook
- pyspark-notebook
- all-spark-notebook
The GitHub repository used to create these is:
Basic Concepts
Source-To-Image (S2I)
Source-to-Image (S2I) is a toolkit and workflow for building reproducible container images from source code. S2I produces ready-to-run images by injecting source code into a container image and letting the container prepare that source code for execution. By creating self-assembling builder images, you can version and control your build environments exactly like you use container images to version your runtime environments.
How it works
Start a container from the builder image with the application source injected into a known directory
The container process transforms that source code into the appropriate runnable setup - in this case, it will create an image stream with tag corresponding to the Python version being used, with the underlying image reference referring to a specific version of the image on quay.io, rather than the latest build. This ensures that the version of the image doesn’t change to a newer version of the image which you haven’t tested.
Goals and benefits
1. Reproducibility
Allow build environments to be tightly versioned by encapsulating them within a container image and defining a simple interface (injected source code) for callers. Reproducible builds are a key requirement to enabling security updates and continuous integration in containerized infrastructure, and builder images help ensure repeatability as well as the ability to swap runtimes.
2. Flexibility
Any existing build system that can run on Linux can be run inside of a container, and each individual builder can also be part of a larger pipeline. In addition, the scripts that process the application source code can be injected into the builder image, allowing authors to adapt existing images to enable source handling.
3. Speed
Instead of building multiple layers in a single Dockerfile, S2I encourages authors to represent an application in a single image layer. This saves time during creation and deployment, and allows for better control over the output of the final image.
4. Security
Dockerfiles are run without many of the normal operational controls of containers, usually running as root and having access to the container network. S2I can be used to control what permissions and privileges are available to the builder image since the build is launched in a single container. In concert with platforms like OpenShift, source-to-image can enable admins to tightly control what privileges developers have at build time.
Routes
An OpenShift Route exposes a service at a host name, like www.example.com , so that external clients can reach it by name. When a Route object is created on OpenShift, it gets picked up by the built-in HAProxy load balancer in order to expose the requested service and make it externally available with the given configuration. You might be familiar with the Kubernetes Ingress object and might already be asking “what’s the difference?”. Red Hat created the concept of Route in order to fill this need and then contributed the design principles behind this to the community; which heavily influenced the Ingress design. Though a Route does have some additional features as can be seen in the chart below.
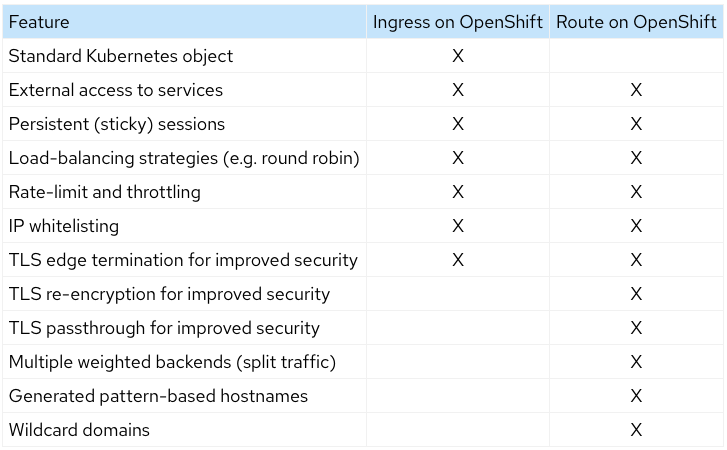
NOTE: DNS resolution for a host name is handled separately from routing; your administrator may have configured a cloud domain that will always correctly resolve to the router, or if using an unrelated host name you may need to modify its DNS records independently to resolve to the router.
Also of note is that an individual route can override some defaults by providing specific configurations in its annotations. See route specific annotations for more details.
ImageStreams
An ImageStream stores a mapping of tags to images, metadata overrides that are applied when images are tagged in a stream, and an optional reference to a Docker image repository on a registry.
What are the benefits?
Using an ImageStream makes it easy to change a tag for a container image. Otherwise to change a tag you need to download the whole image, change it locally, then push it all back. Also promoting applications by having to do that to change the tag and then update the deployment object entails many steps. With ImageStreams you upload a container image once and then you manage it’s virtual tags internally in OpenShift. In one project you may use the dev tag and only change reference to it internally, in prod you may use a prod tag and also manage it internally. You don’t really have to deal with the registry!
You can also use ImageStreams in conjunction with DeploymentConfigs to set a trigger that will start a deployment as soon as a new image appears or a tag changes its reference.
See below for more details:
Builds
A build is the process of transforming input parameters into a resulting object. Most often, the process is used to transform input parameters or source code into a runnable image. A BuildConfig object is the definition of the entire build process.
OpenShift Container Platform leverages Kubernetes by creating Docker-formatted containers from build images and pushing them to a container image registry.
Build objects share common characteristics: inputs for a build, the need to complete a build process, logging the build process, publishing resources from successful builds, and publishing the final status of the build. Builds take advantage of resource restrictions, specifying limitations on resources such as CPU usage, memory usage, and build or pod execution time.
See Understanding image builds for more details.