ARO with Nvidia GPU Workloads
This content is authored by Red Hat experts, but has not yet been tested on every supported configuration.
ARO guide to running Nvidia GPU workloads.
Prerequisites
- oc cli
- Helm
- jq, moreutils, and gettext package
- An ARO 4.14 cluster
Note: If you need to install an ARO cluster, please read our ARO Terraform Install Guide . Please be sure if you’re installing or using an existing ARO cluster that it is 4.14.x or higher.
Note: Please ensure your ARO cluster was created with a valid pull secret (to verify make sure you can see the Operator Hub in the cluster’s console). If not, you can follow these instructions.
Linux:
MacOS:
Helm Prerequisites
If you plan to use Helm to deploy the GPU operator, you will need do the following
-
Add the MOBB chart repository to your Helm
-
Update your repositories
GPU Quota
All GPU quotas in Azure are 0 by default. You will need to login to the azure portal and request GPU quota. There is a lot of competition for GPU workers, so you may have to provision an ARO cluster in a region where you can actually reserve GPU.
ARO supports the following GPU workers:
- NC4as T4 v3
- NC6s v3
- NC8as T4 v3
- NC12s v3
- NC16as T4 v3
- NC24s v3
- NC24rs v3
- NC64as T4 v3
Please remember that when you request quota that Azure is per core. To request a single NC4as T4 v3 node, you will need to request quota in groups of 4. If you wish to request an NC16as T4 v3 you will need to request quota of 16.
-
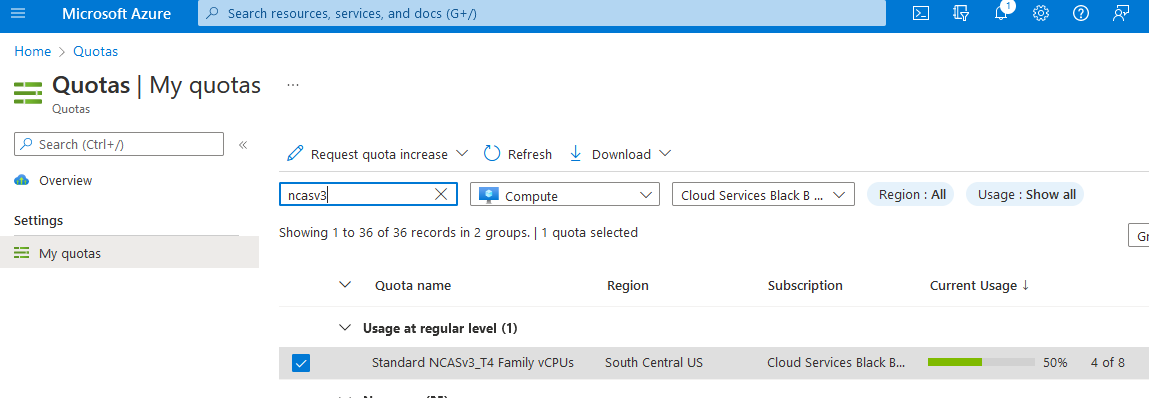
Login to azure
Login to portal.azure.com , type “quotas” in search by, click on Compute and in the search box type “NCAsv3_T4”. Select the region your cluster is in (select checkbox) and then click Request quota increase and ask for quota (I chose 8 so i can build two demo clusters of NC4as T4s). The Helm chart we use below will request a single
Standard_NC4as_T4_v3machine. -
Configure quota
Log in to your ARO cluster
-
Login to OpenShift - we’ll use the kubeadmin account here but you can login with your user account as long as you have cluster-admin.
GPU Machine Set
ARO still uses Kubernetes Machinsets to create a machine set. I’m going to export the first machine set in my cluster (az 1) and use that as a template to build a single GPU machine in southcentralus region 1.
You can create the machine set the easy way using Helm, or Manually. We recommend using the Helm chart method.
Option 1 - Helm
-
Create a new machine-set (replicas of 1), see the Chart’s values file for configuration options
-
Switch to the proper namespace (project):
-
Wait for the new GPU nodes to be available
-
Skip past Option 2 - Manually to Install Nvidia GPU Operator
Option 2 - Manually
-
View existing machine sets
For ease of set up, I’m going to grab the first machine set and use that as the one I will clone to create our GPU machine set.
-
Save a copy of example machine set
-
Change the .metadata.name field to a new unique name
I’m going to create a unique name for this single node machine set that shows nvidia-worker-
that follows a similar pattern as all the other machine sets. -
Ensure spec.replicas matches the desired replica count for the MachineSet
-
Change the .spec.selector.matchLabels.machine.openshift.io/cluster-api-machineset field to match the .metadata.name field
-
Change the .spec.template.metadata.labels.machine.openshift.io/cluster-api-machineset to match the .metadata.name field
-
Change the spec.template.spec.providerSpec.value.vmSize to match the desired GPU instance type from Azure.
The machine we’re using is Standard_NC4as_T4_v3.
-
Change the spec.template.spec.providerSpec.value.zone to match the desired zone from Azure
-
Delete the .status section of the yaml file
-
Verify the other data in the yaml file.
Create GPU machine set
These steps will create the new GPU machine. It may take 10-15 minutes to provision a new GPU machine. If this step fails, please login to the azure portal and ensure you didn’t run across availability issues. You can go “Virtual Machines” and search for the worker name you created above to see the status of VMs.
-
Create GPU Machine set
This command will take a few minutes to complete.
-
Verify GPU machine set
Machines should be getting deployed. You can view the status of the machine set with the following commands
Once the machines are provisioned, which could take 5-15 minutes, machines will show as nodes in the node list.
You should see a node with the “nvidia-worker-southcentralus1” name it we created earlier.
Install Nvidia GPU Operator
This will create the nvidia-gpu-operator name space, set up the operator group and install the Nvidia GPU Operator.
Like ealier you can do it the easy way with Helm, or the hard way by doing it manually.
Option 1 - Helm
-
Create namespaces
-
Use the
mobb/operatorhubchart to deploy the needed operators -
Wait until the two operators are running
Note: If you see an error like Error from server (NotFound): deployments.apps “nfd-controller-manager” not found, wait a few minutes and try again.
-
Install the Nvidia GPU Operator chart
-
Skip past Option 2 - Manually to Validate GPU
Option 2 - Manually
-
Create Nvidia namespace
-
Create Operator Group
-
Get latest nvidia channel
If your cluster was created without providing the pull secret, the cluster won’t include samples or operators from Red Hat or from certified partners. This will result in the following error message:
Error from server (NotFound): packagemanifests.packages.operators.coreos.com “gpu-operator-certified” not found.
To add your Red Hat pull secret on an Azure Red Hat OpenShift cluster, follow this guidance .
-
Get latest nvidia package
-
Create Subscription
-
Wait for Operator to finish installing
Don’t proceed until you have verified that the operator has finished installing. It’s also a good point to ensure that your GPU worker is online.
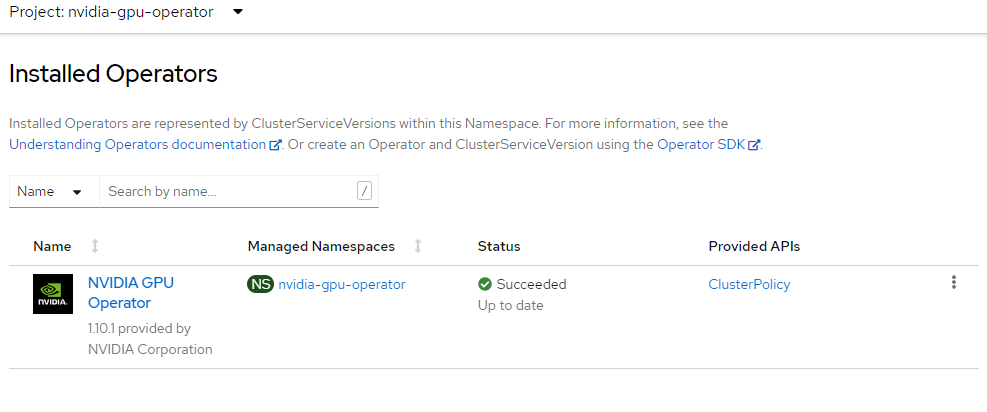
Install Node Feature Discovery Operator
The node feature discovery operator will discover the GPU on your nodes and appropriately label the nodes so you can target them for workloads. We’ll install the NFD operator into the opneshift-ndf namespace and create the “subscription” which is the configuration for NFD.
Official Documentation for Installing Node Feature Discovery Operator
-
Set up Name Space
-
Create OperatorGroup
-
Create Subscription
-
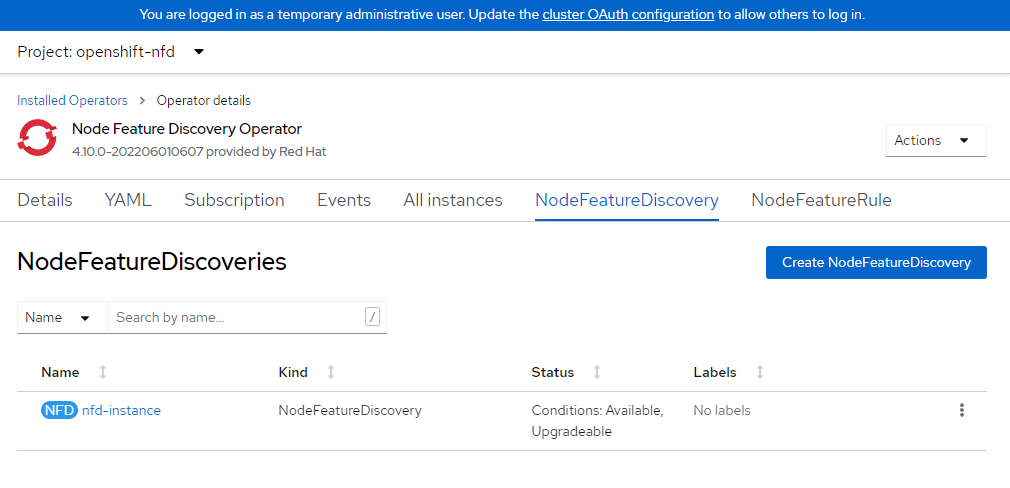
Wait for Node Feature discovery to complete installation
You can login to your openshift console and view operators or simply wait a few minutes. The next step will error until the operator has finished installing.
-
Create NFD Instance
-
Verify NFD is ready.
This operator should say Available in the status
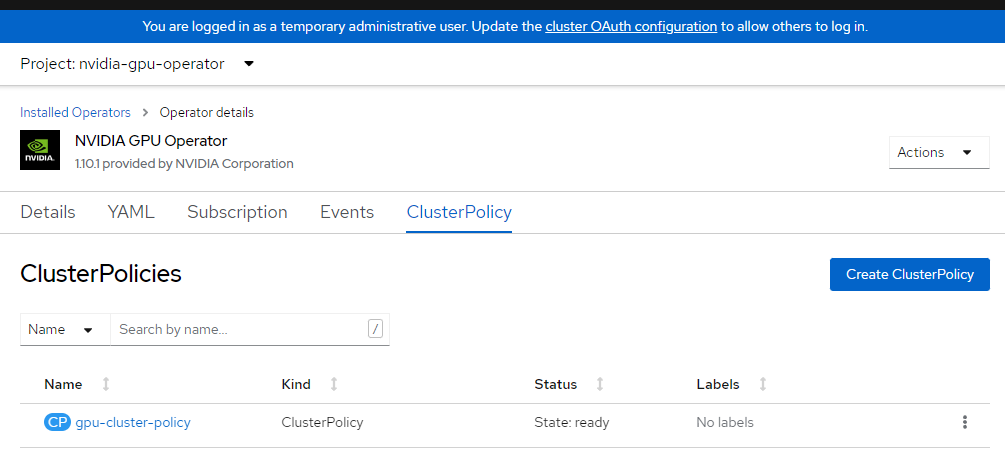
Apply nVidia Cluster Config
We’ll now apply the nvidia cluster config. Please read the nvidia documentation on customizing this if you have your own private repos or specific settings. This will be another process that takes a few minutes to complete.
-
Apply cluster config
-
Verify Cluster Policy
Login to OpenShift console and browse to operators and make sure you’re in nvidia-gpu-operator namespace. You should see it say State: Ready once everything is complete.
Validate GPU
It may take some time for the nVidia Operator and NFD to completely install and self-identify the machines. These commands can be ran to help validate that everything is running as expected.
-
Verify NFD can see your GPU(s)
You should see output like:
-
Verify node labels
-
Wait until Cluster Policy is ready
Note: This step may take a few minutes to complete.
-
Nvidia SMI tool verification
You should see output that shows the GPUs available on the host such as this example screenshot. (Varies depending on GPU worker type)
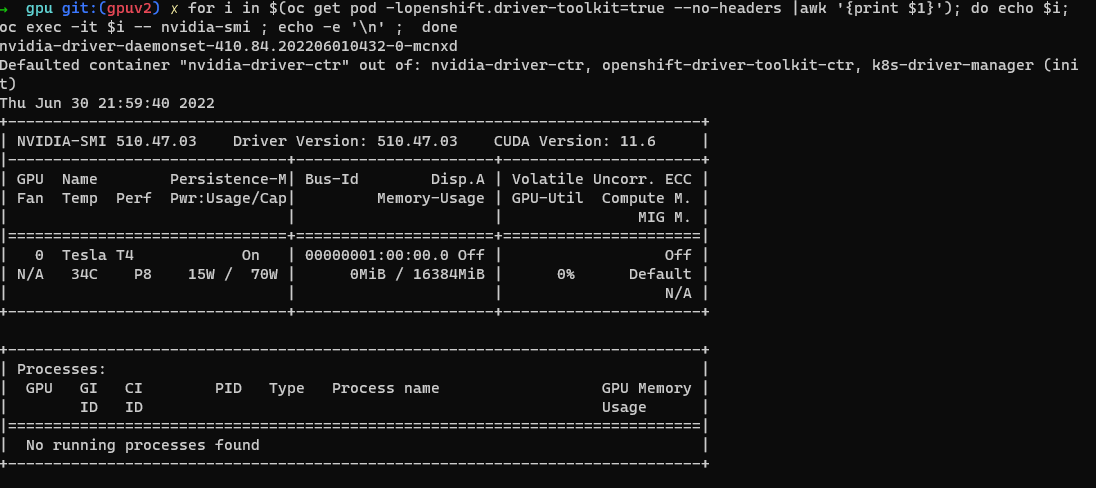
-
Create Pod to run a GPU workload
-
View logs
Please note, if you get an error “Error from server (BadRequest): container “cuda-vector-add” in pod “cuda-vector-add” is waiting to start: ContainerCreating”, try running “oc delete pod cuda-vector-add” and then re-run the create statement above. I’ve seen issues where if this step is ran before all of the operator consolidation is done it may just sit there.
You should see Output like the following (mary vary depending on GPU):
-
If successful, the pod can be deleted