
A new OpenShift 4 feature was added to OpenShift Cluster Manager in the summer 2020, Insights for OpenShift 4. The full introduction of this feature is here: https://www.openshift.com/blog/openshift-insights-for-openshift-cluster-manager
Insights for OpenShift is a set of health checks, added by OpenShift support, engineering, or other subject matter experts, and allows customers to identify and prevent potential issues before they impact their clusters or remediate issues already present on their clusters. Health checks are either based on an existing bug and customer issues or on issues discovered during our testing. Often we also add health checks based on analyzing the telemetry and insights data when observing suspicious behaviour in the data. It’s important to mention that health checks allow us to deal with issues that can’t be or are not yet fixed in the product. Our aim is to always fix an issue or introduce ways to prevent potential problems in OpenShift directly, usually by adding new logic to operators or by simply fixing a bug. Insights also helps us mitigate situations in which fixing the product itself is not possible or issues are caused by misconfigurations or specific conditions. In all cases, Insights will give you remediation steps that you can review, copy-paste, and run as `oc adm` on your cluster. These steps are tailored to your cluster and give you the exact hostname/podname to run against. Each health check also carries information about criticality level. The most critical health checks are those that can cause a service disruption and/or performance degradation after an upgrade or some change on your cluster. We recommend executing the most important remediations immediately. Lower priority remediations might be just recommendations or best practices and in some cases, there might be good reasons why you have a setting on your cluster that is triggering a health check. In such a case, OCM allows you to silence the check.
Over the last couple months since we introduced the feature, we added over a hundred different health checks, and today I’m going to walk you through some of the interesting ones. For each cluster, you’ll find the results of Insights analysis in OpenShift Cluster Manager. The URL looks like this: https://cloud.redhat.com/openshift/details/($clusterid)#insights. Also, since the introduction of OpenShift 4.7, there’s a new Insights dashboard on the overview page of OpenShift WebConsole that leads you directly into OpenShift Cluster Manager and offers you the remediation steps.
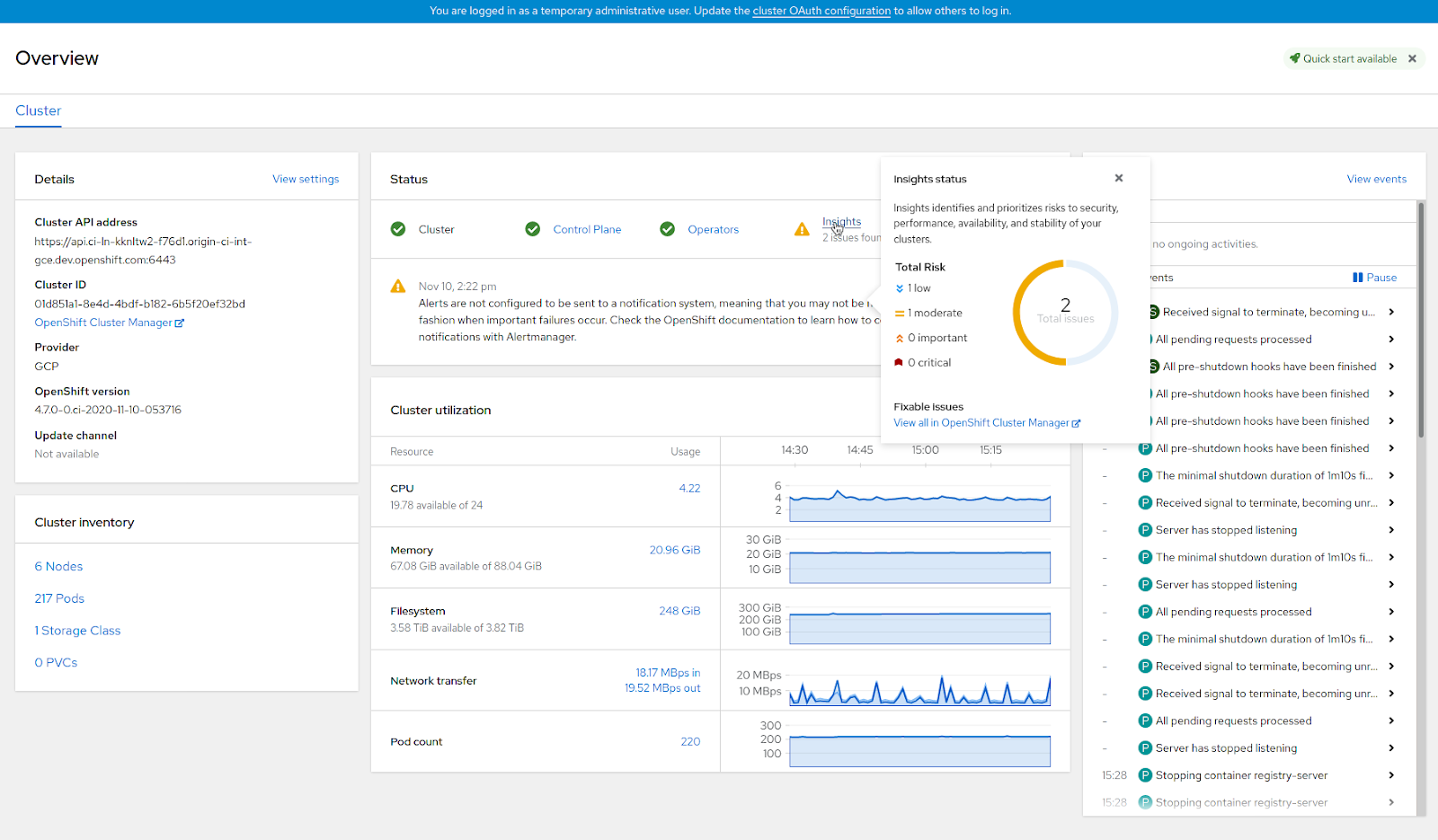
Let’s go to some of the examples, starting with the most simple ones. One of the most common problems is when pods start to fail. This can happen for many reasons, such as not properly initialized, not ready or scheduled, or the containers running are failing, frequently restarting and causing some disruption. In this case, Insights will give you a list of pods and containers causing this disruption and suggest steps to fix them. Similar to the previous example, we check for failing operators. There might be various reasons why this happens, from unfinished updates, degraded states, or simply not being available/failing to start or restart.
Quite a typical issue with newly span clusters is that nodes are not configured according to best practices. While initially the cluster is not under heavy load, this might not be a problem, but later, when the cluster is under pressure of apps, the condition can swiftly trigger an outage of the whole cluster and apps running on it. In this case, we identify the nodes and suggest corrective actions on those that are not performing well.
There are many checks aimed at day-two operations as well. Quite a common cause for cluster failures is inconsistent maintenance of nodes. For instance, inconsistent versions of container runtime may be deployed on OCP nodes. The condition can cause failures of pod startups as well as scheduling and balancing problems. Similar to that, we warn users when an unsupported version of OCP is running on the cluster. In both cases, we recommend specific steps to finish an upgrade of the components or ways to safely upgrade to the latest supported version of OpenShift Container Platform.
An example of a specific bug health check would be a check for mutation of security context constraints (SCCs). SCCs, or rather their default configuration files, are supposed to stay intact and unchanged. In case of hundreds of clusters, these files were mistakenly modified by their administrators, resulting in failure to upgrade their clusters to newer versions of the product. Insights alerts on the issue and provides remediation steps guiding administrators through a workaround.
As mentioned above, new health checks are being added every day based on our findings, new types of issues but also based on analysis of all the data that we get from OpenShift clusters. Thanks for helping us to improve the product and we hope you’ll find these health checks useful!
About the author

Radek Vokal started with Red Hat in 2004 as a software engineer, later lead team responsible for core Red Hat Enteprirse Linux components and core Kubernetes teams. Currently he is the Senior Manager of Product Management for Insights OpenShift services and is based in Brno, Czech Republic.
More like this
Browse by channel

Automation
The latest on IT automation that spans tech, teams, and environments

Artificial intelligence
Explore the platforms and partners building a faster path for AI

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
Explore how we reduce risks across environments and technologies

Edge computing
Updates on the solutions that simplify infrastructure at the edge

Infrastructure
Stay up to date on the world’s leading enterprise Linux platform

Applications
The latest on our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech
Products
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud services
- See all products
Tools
- Training and certification
- My account
- Developer resources
- Customer support
- Red Hat value calculator
- Red Hat Ecosystem Catalog
- Find a partner
Try, buy, & sell
Communicate
About Red Hat
We’re the world’s leading provider of enterprise open source solutions—including Linux, cloud, container, and Kubernetes. We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
Select a language
Red Hat legal and privacy links
- About Red Hat
- Jobs
- Events
- Locations
- Contact Red Hat
- Red Hat Blog
- Diversity, equity, and inclusion
- Cool Stuff Store
- Red Hat Summit