
Crunchy Data is a leading provider of trusted open source PostgreSQL and PostgreSQL support, technology and training. Crunchy Data is also a Red Hat Technology Connect Partner and active collaborator with OpenShift.
For some time, Crunchy Data has been collaborating with the Red Hat OpenShift team to in order to developed an open source, highly scalable PostgreSQL container that leverages the security and volume features of OpenShift. The resulting PostgreSQL image developed by Crunchy and the OpenShift team is fully open source and available on github at https://github.com/CrunchyData/crunchy-postgres-container-94.
This Crunchy PostgreSQL image offers:
- The latest PostgreSQL database (9.4) open source bits
- Standalone database creation
- Streaming replication cluster creation
- Tune parameters via environment variables
- Use local storage or NFS
Several example templates are made available in the github repo in order to make getting started easy.
PostgreSQL Streaming Replication in Openshift
What does this mean for OpenShift users interested in Postgres? Let’s take a look at the streaming cluster replication template to see how easy Crunchy makes it to get moving with an advanced PostgreSQL setup under OpenShift 3.1:
espresso jeffmc~/crunchy-postgres-container-94/openshift]: oc process -f
./master-slave-rc.json | oc create -f -
service "pg-master-rc" created
service "pg-slave-rc" created
deploymentconfig "pg-master-rc" created
deploymentconfig "pg-slave-rc" created
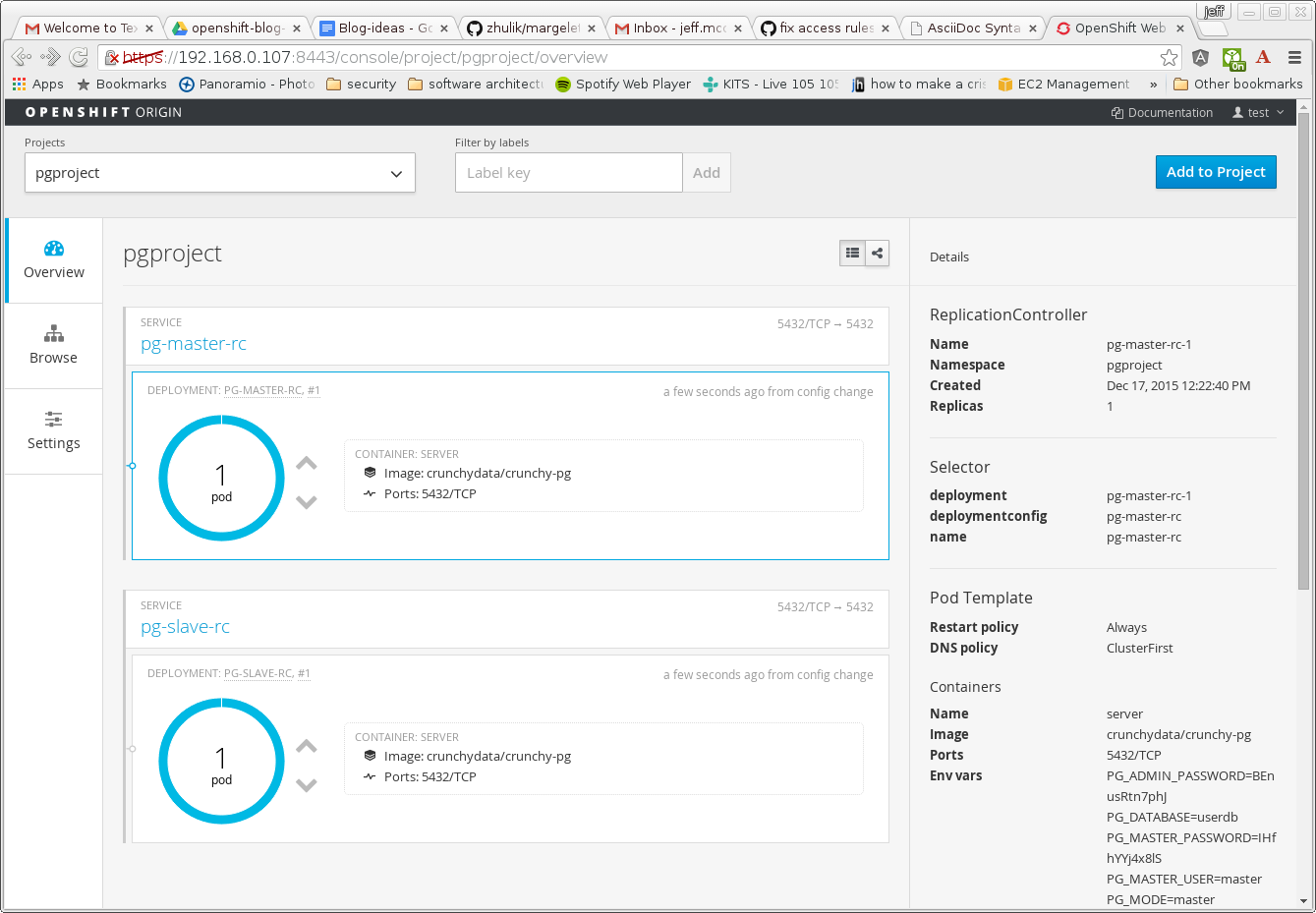
After the master and slave pods are created, you will see the following in the OpenShift console:

The Crunchy PostgreSQL templates leverage the “Replication Controller” API resource. A Replication Controller represents a set of pods which are replicas of one another. Replication Controllers can be resized, resulting in replicas being created or destroyed to achieve the desired number of replicas. Using a Replication Controller to replicate pods running the Crunchy PostgreSQL image allows the user to scale up the number of PostgreSQL standby containers on demand using the Replication Controller scale command.
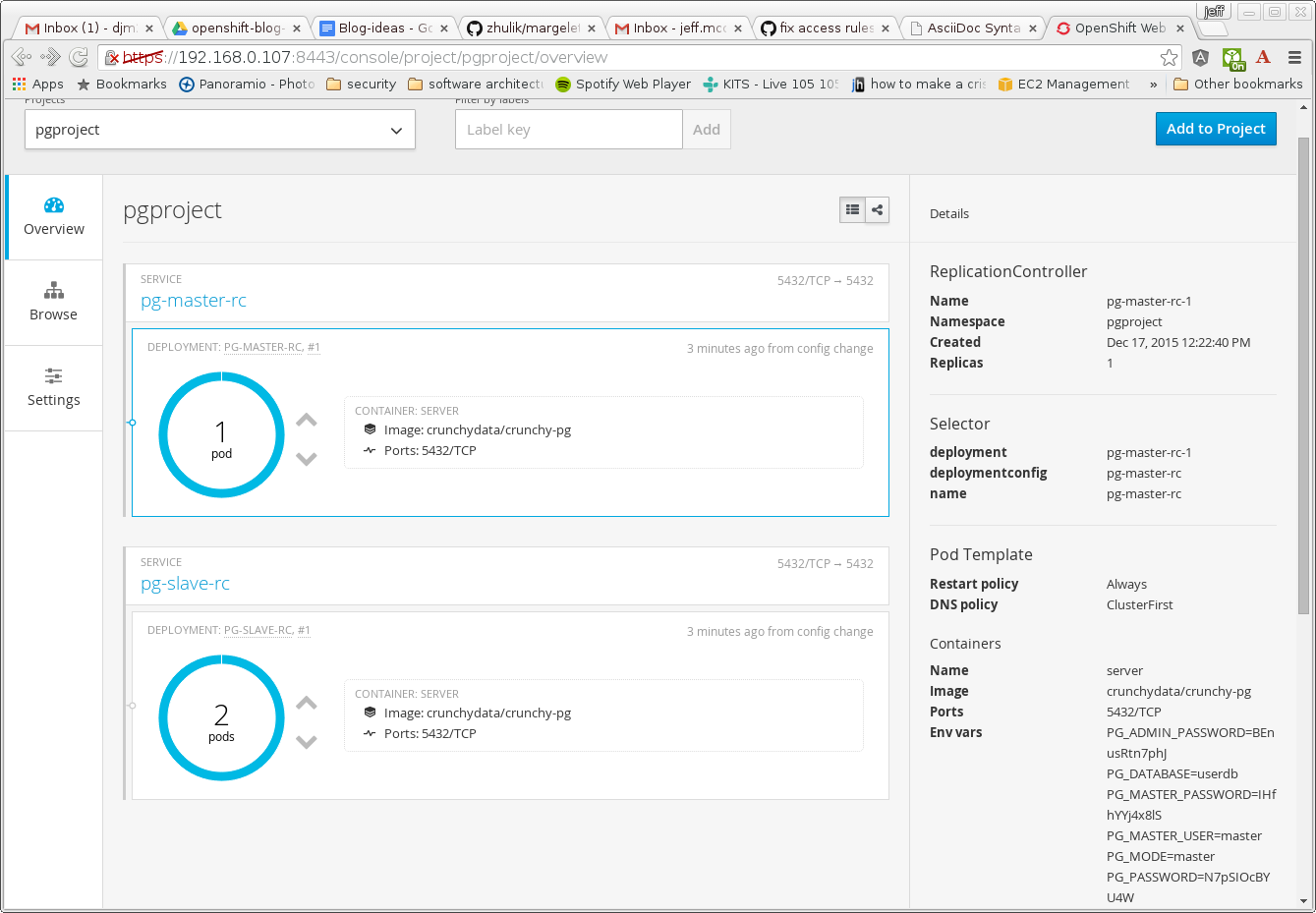
For example, in OpenShift you can scale up the Postgresql standby containers as follows:
oc scale rc pg-slave-rc-1 --replicas=2
For more information on OpenShift Replication Controllers, following this link:
https://docs.openshift.com/enterprise/3.0/architecture/core_concepts/deployments.html
After this command is executed, you will see that the slave has scaled up in the OpenShift console:

{kind=link}
{kind=link}
You can now connect to the master database, create objects/populate tables, and the changes will be replicated to the slave databases. The slaves are read-only and the master is read-write. So, your application will need to take this into account when doing reads/writes and connect to the correct database. That leads us to a future blog topic, running a Postgresql-aware load balancer/proxy such as pg-pool (http://www.pgpool.net/mediawiki/index.php/Main_Page ) as a pod.
You can test the Postgresql connections by using the psql client as follows:
psql -h pg-master-rc.pgproject.svc.cluster.local -U testuser userdb
psql -h pg-slave-rc.pgproject.svc.cluster.local -U testuser userdb
The passwords are auto-generated and are stored as environment variables within the pod metadata. You can find the passwords by running the following commands:
oc get pods
oc describe pod <<<pod name>>> | grep PG_PASSWORD
This example has used an Openshift project called pgproject so you end up with a fully qualified domain name of pg-master-rc.pgproject.svc.cluster.local for the service.
PostgreSQL Data Storage Options in Openshift
The Crunchy PostgreSQL image supports both host-local and NFS storage options for data. The templates for OpenShift leverage the security context functionality of OpenShift to run the PostgreSQL in a container that does not require root access or additional capabilities. Some containers and the applications they run have specific requirements about what UID they will execute as. For example, the PostgreSQL database requires it be run as the postgres (UID 26) user.
The image and examples found in this blog post are found here:github.com/crunchydata/crunchy-postgresql-container-94
https://github.com/CrunchyData/crunchy-postgres-container-94/tree/master/openshift
Various examples of running PostgreSQL are included that show the OpenShift security capabilities.
PostgreSQL UID in Openshift
There are a couple of ways in OpenShift to allow the PostgreSQL database to run as the postgres UID. We’ll cover both coarse-grained and finer-grained examples that users might deploy PostgreSQL with.
Per-Pod Security Context Setting
A fine grained way to provide this same capability to the Crunchy PostgreSQL container is by specifying a security context in the pod template itself. This is demonstrated in the ‘standalone-runasuser.json’ file. Here is the portion of that template you will take note of:
"securityContext": {
"runAsUser" : 26
},
This setting specifies to OpenShift that this pod should be run as the UID 26, which maps to the postgres user.
Within the Openshift security context file, you will specify the runAsUser.Type setting to MustRunAsNonRoot:
runAsUser:
type: MustRunAsNonRoot
To execute the example, perform the following deployment commands in OpenShift:
cd crunchy-postgresql-container-94/openshift
oc login
oc process -f standalone-runasuser.json | oc create -f -
Global Security Context Setting
A coarser-grained approach is to modify the security context constaint for the namespace to allow pods to run as any user. You can modify these settings by the following command within your Openshift deployment:
oc edit scc restricted --config=./openshift.local.config/master/admin.kubeconfig
Within the Security Context Constraints, you will specify the runAsUser.Type setting to RunAsAny:
runAsUser:
type: RunAsAny
This is a coarse-grained way of opening up OpenShift’s security to allow any pod/container to run as any user. This security setting might be too permissive for many environments.
Using Secrets for PostgreSQL Credentials
Another Openshift security feature that can be used for PostgreSQL containers is to obtain username and passwords from a secret. A secret is a concept within Openshift that allows any sort of secret or private information to be consumed in a volume in a container. Secrets allow credentials to be used independently of where they are defined, and to be used without leaking secret information into the places where processes that use them are defined. For more information on “secrets” within OpenShift, please see here: https://docs.openshift.com/enterprise/3.0/dev_guide/secrets.html
Using the following commands, we can establish some usernames and passwords to be used within PostgreSQL:
oc secrets new-basicauth pgroot --username=postgres --password=postgrespsw
oc secrets new-basicauth pgmaster --username=master --password=masterpsw
oc secrets new-basicauth pguser --username=testuser --password=somepassword
These usernames and passwords (made “secrets” by OpenShift) are then populated in a volume mounted into a PostgreSQL container the credentials can be read from the file system. The secret data is stored in a tmpfs filesystem so that it does not come to rest on nodes where pods use the secret and isolated with SELinux so that other containers cannot use it.
You can view the secrets that have been created by running the following command:
oc get secrets
You can see examples of referencing a secret within a container by looking at the example templates here:
- standalone-secret.json (an example that deploys a single PostgreSQL database)
- master-slave-rc-secret.json (an example of deploying a master-slave PostgreSQL configuration that can be scaled up using replication controllers)
Secrets are consumed by pods via volumes within your container specification:
"volumes": [{
"name": "pgdata",
"emptyDir": {}
}, {
"name": "pguser-volume",
"secret": {
"secretName": "pguser"
}
},
.
.
.
"volumeMounts": [{
"mountPath": "/pgdata",
"name": "pgdata",
"readOnly": false
}, {
"mountPath": "/pguser",
"name": "pguser-volume"
}
Scripts within the container can then reference the secrets by referring to the mounted volumes as specified in the template.
Secrets provide yet another way for a database container to fetch login credentials other than passing them via environment variables.
Next Steps
In upcoming releases of the Crunchy Postgresql container, support for automated deployment of a pgpool pod will be explored, as well as an upgrade to the soon to be released PostgreSQL 9.5.
For additional information about running PostgreSQL containers in OpenShift or for information about Crunchy Data’s commercial PostgreSQL support offerings, please contact info@crunchydata.com or visit www.crunchydata.com.
About Crunchy Data
Crunchy Data is a leading provider of trusted open source PostgreSQL and PostgreSQL support, technology and training. Crunchy Data is the provider of Crunchy Certified PostgreSQL, an open source PostgreSQL 9.5 distribution including popular extensions such as PostGIS and enhanced audit logging capability. Crunchy Certified PostgreSQL is currently “In Evaluation” for Common Criteria certification at the EAL2+ level.
When combined with Crunchy’s Secure Enterprise Support, Crunchy Certified PostgreSQL provides enterprises with an open source and trusted relational database management solution backed by enterprise support from leading experts in PostgreSQL technology. For enterprises requiring dedicated PostgreSQL support, Crunchy provides on-premise PostgreSQL professional services and PostgreSQL training. Learn more at www.crunchydata.com
Author
Jeff McCormick
Software Architect
at Crunchy Data Solutions
https://github.com/CrunchyData/crunchy-postgresql-manager
https://github.com/CrunchyData/crunchy-postgres-container-94
About the author

Jeff McCormick works in the Openshift Operator Framework group at Red Hat, focused on Operator technologies.
More like this
Browse by channel

Automation
The latest on IT automation that spans tech, teams, and environments

Artificial intelligence
Explore the platforms and partners building a faster path for AI

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
Explore how we reduce risks across environments and technologies

Edge computing
Updates on the solutions that simplify infrastructure at the edge

Infrastructure
Stay up to date on the world’s leading enterprise Linux platform

Applications
The latest on our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech
Products
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud services
- See all products
Tools
- Training and certification
- My account
- Developer resources
- Customer support
- Red Hat value calculator
- Red Hat Ecosystem Catalog
- Find a partner
Try, buy, & sell
Communicate
About Red Hat
We’re the world’s leading provider of enterprise open source solutions—including Linux, cloud, container, and Kubernetes. We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
Select a language
Red Hat legal and privacy links
- About Red Hat
- Jobs
- Events
- Locations
- Contact Red Hat
- Red Hat Blog
- Diversity, equity, and inclusion
- Cool Stuff Store
- Red Hat Summit